Overview of MMEvol: Instruction evolution and instruction elimination synergistically collaborate through multiple rounds to enhance the diversity and complexity of instruction data.
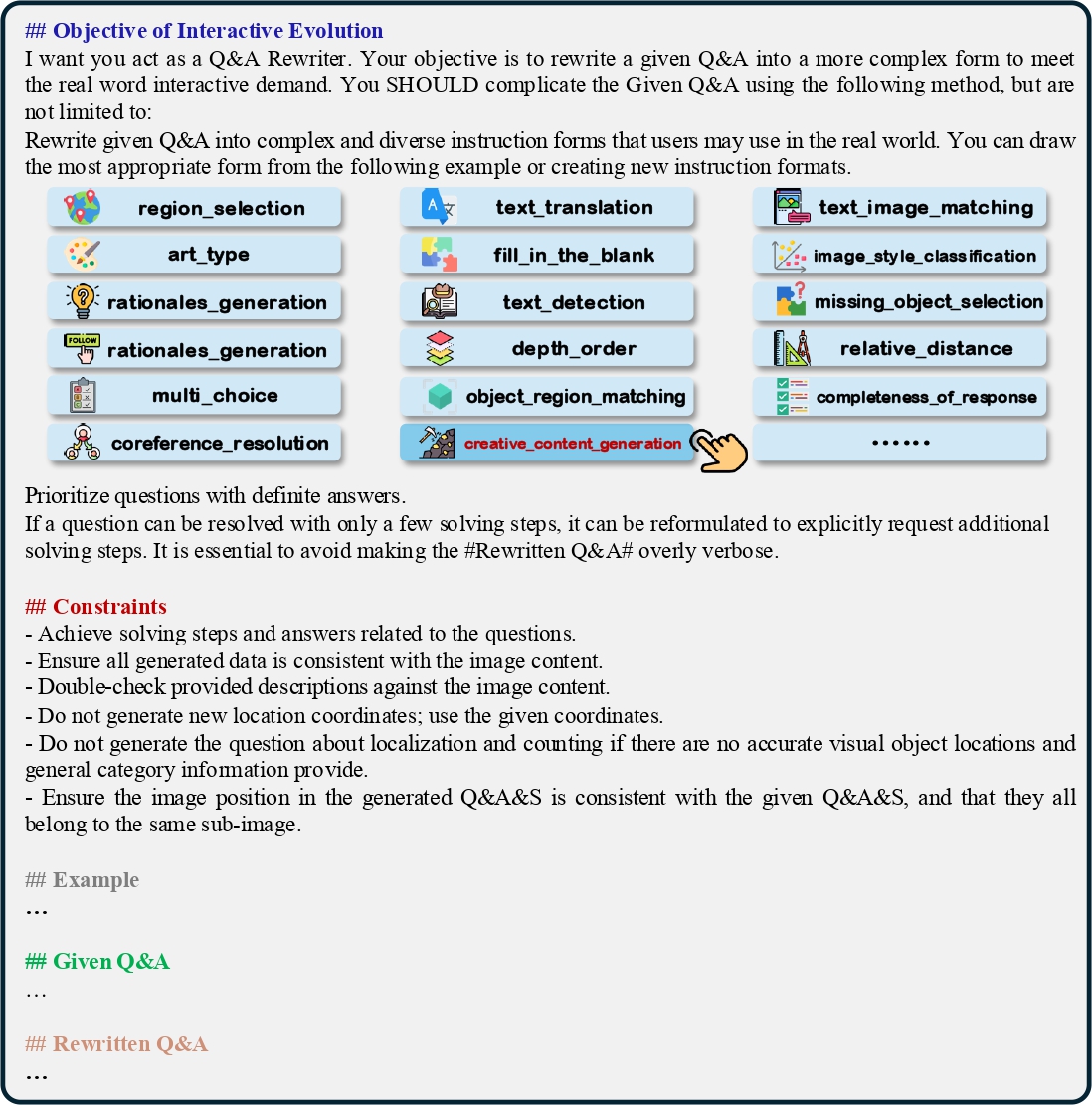
The Prompt Template of Cognitive Reasoning Evolution, Interactive Evolution, Fine-grained Perceptual Evolution and Instruction Elimination.




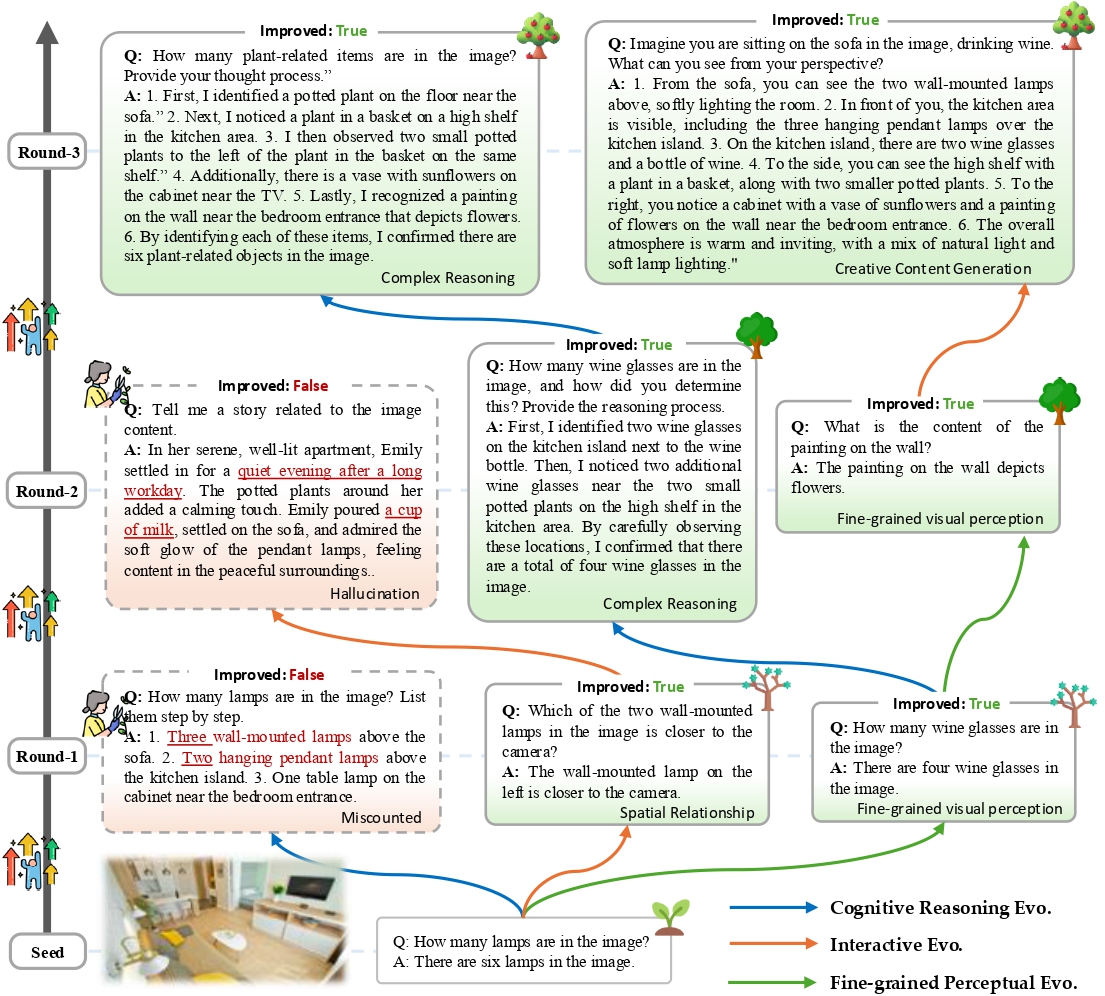
Evolution Case: MMEvol continuously enhances instruction data complexity and diversity over evol-instruct. The sample is from SEED-163K. We mark fine-grained visual information in red, new instructions form in green, and longer reasoning steps in blue.
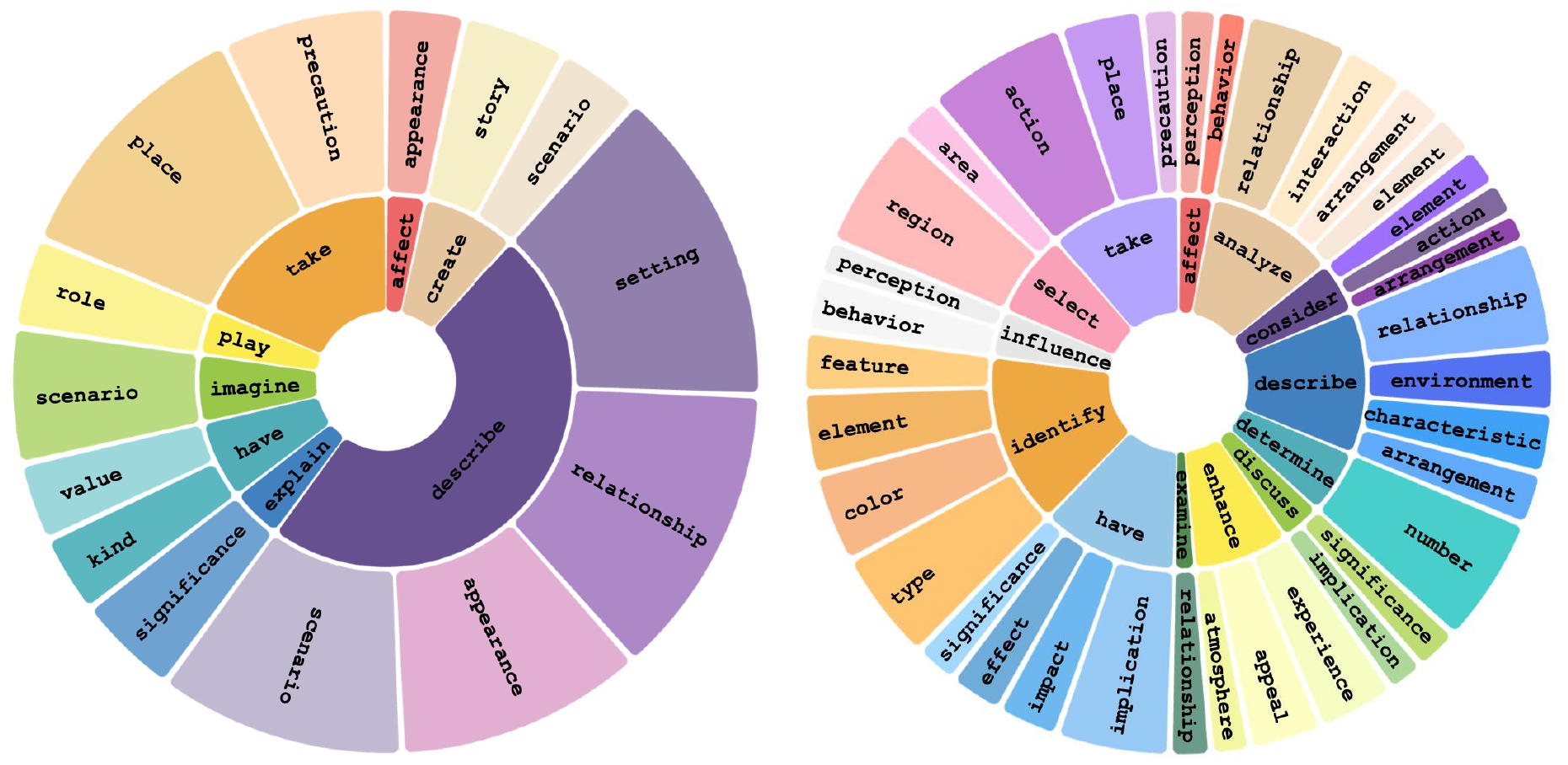
Task Categories: The root verbs (inner circle) and their top noun objects (outer circle) of the seed data in Left and the evolved data in Right. MMEvol can significantly enhance the diversity of instruction data.
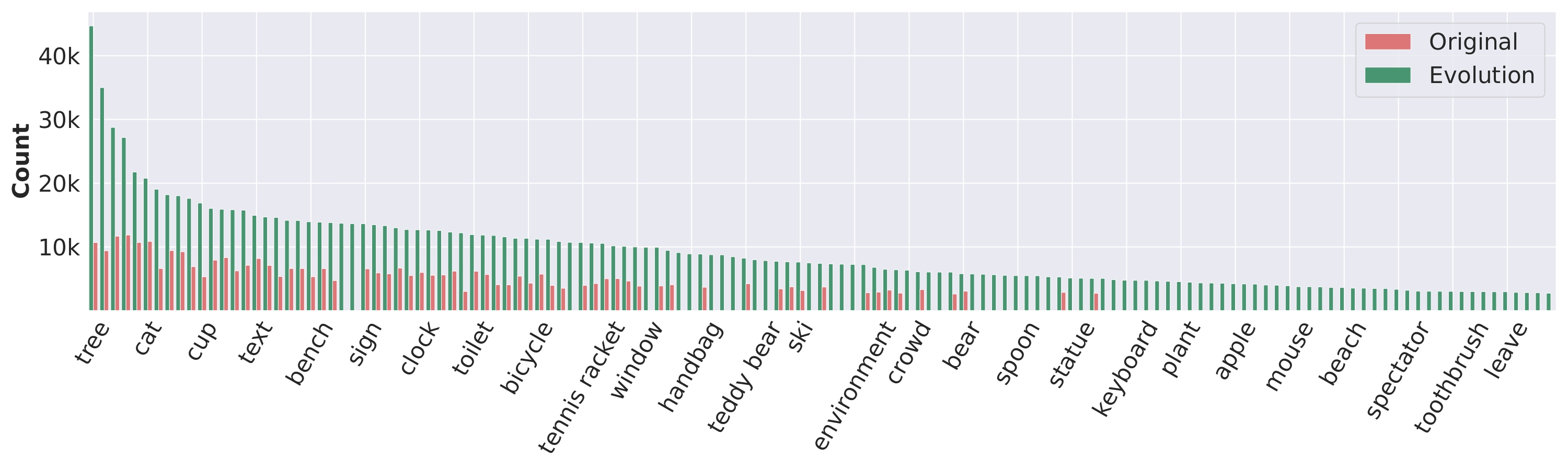
The long-tail distribution of 200 visual objects between seed and evolved data. : MMEvol significantly improves the long-tail distribution of visual objects in the seed data, providing more fine-grained visual information, thereby boosting the model's generalization ability and robustness against hallucinations.
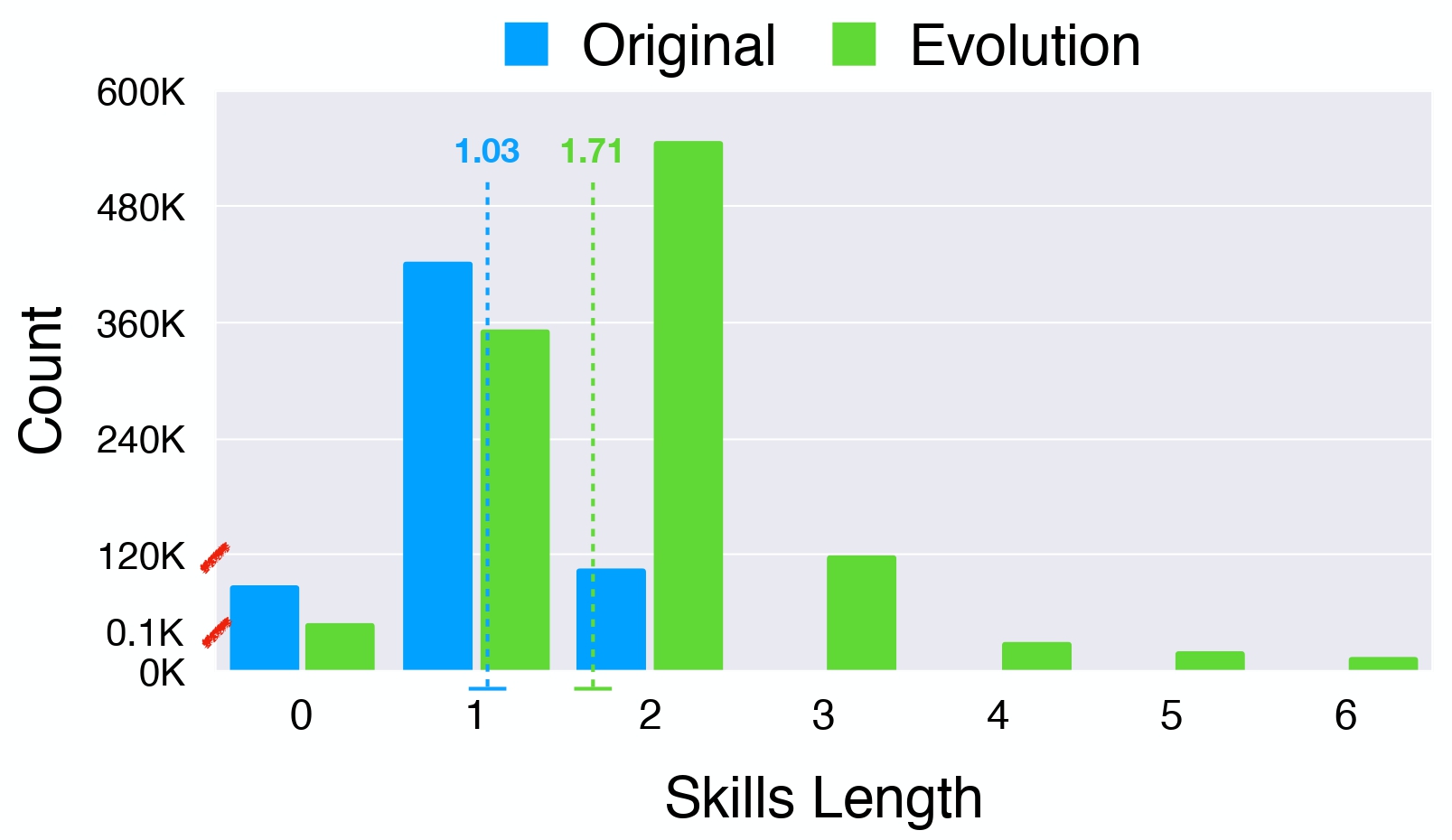
(1) The skills length distribution between the seed data and our evolved data.
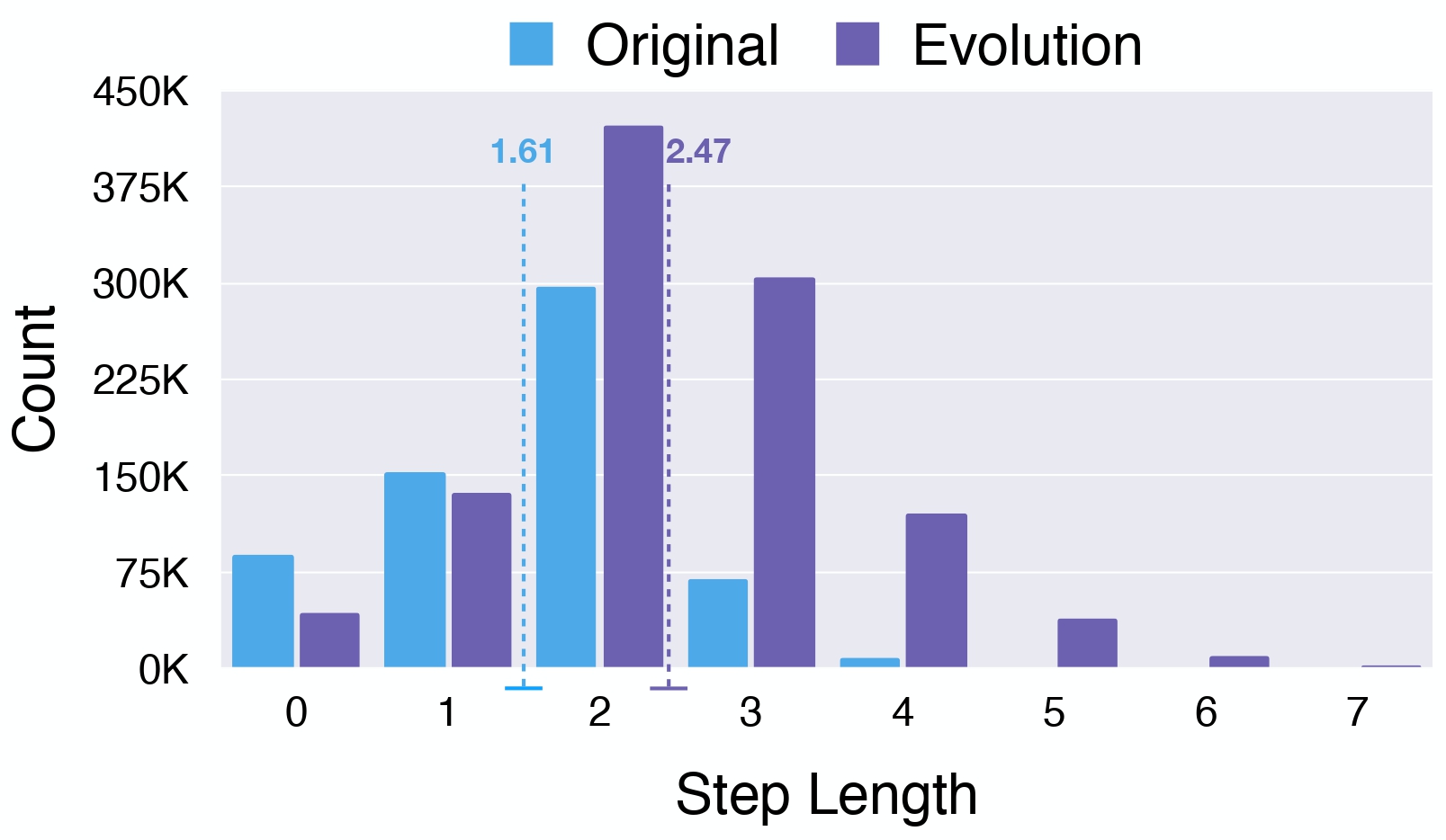
(2) The reasoning steps length distribution between the seed data and our evolved data.
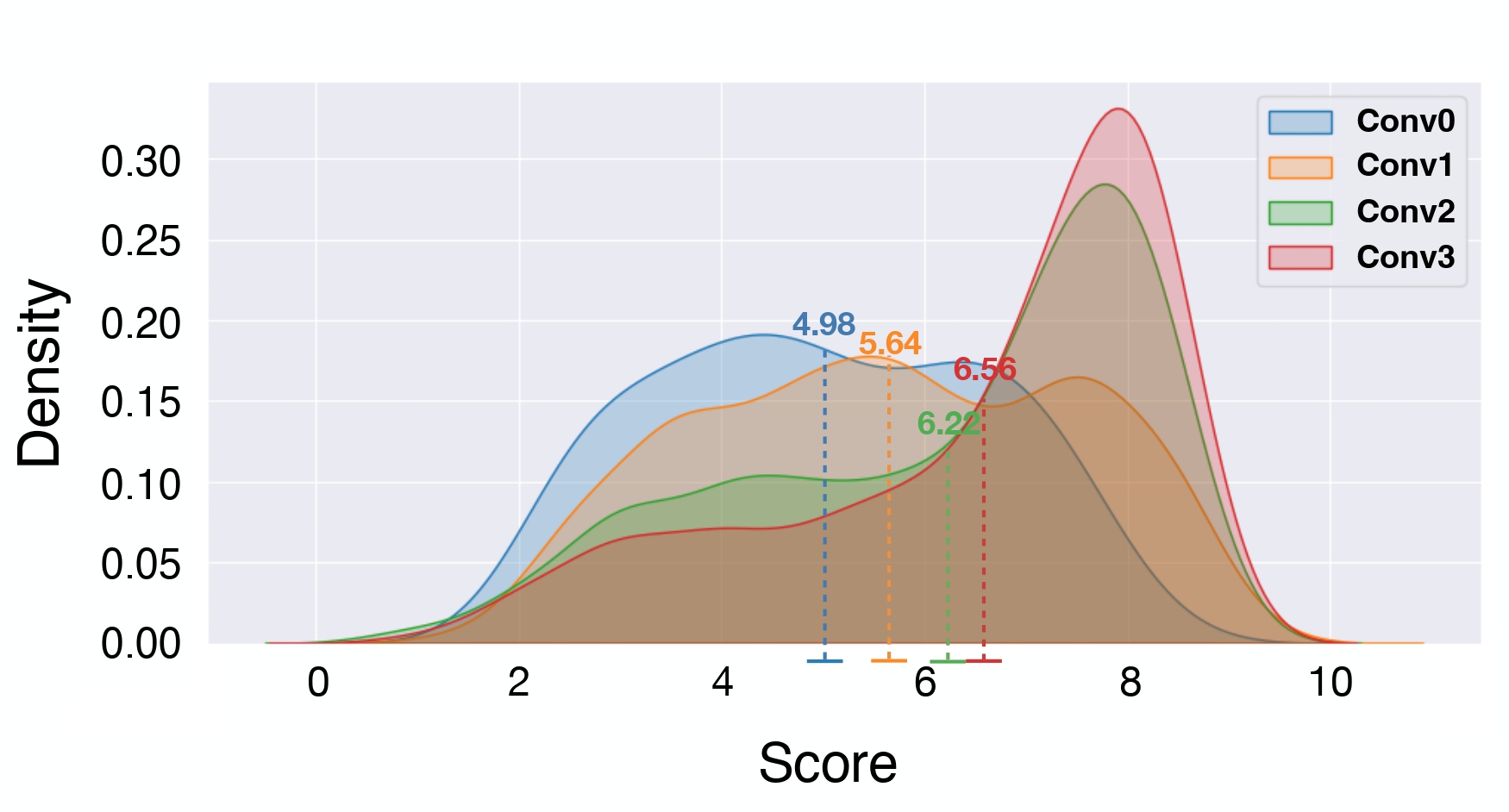
(3) The difficulty and complexity level distribution between the seed data and our evolved data.
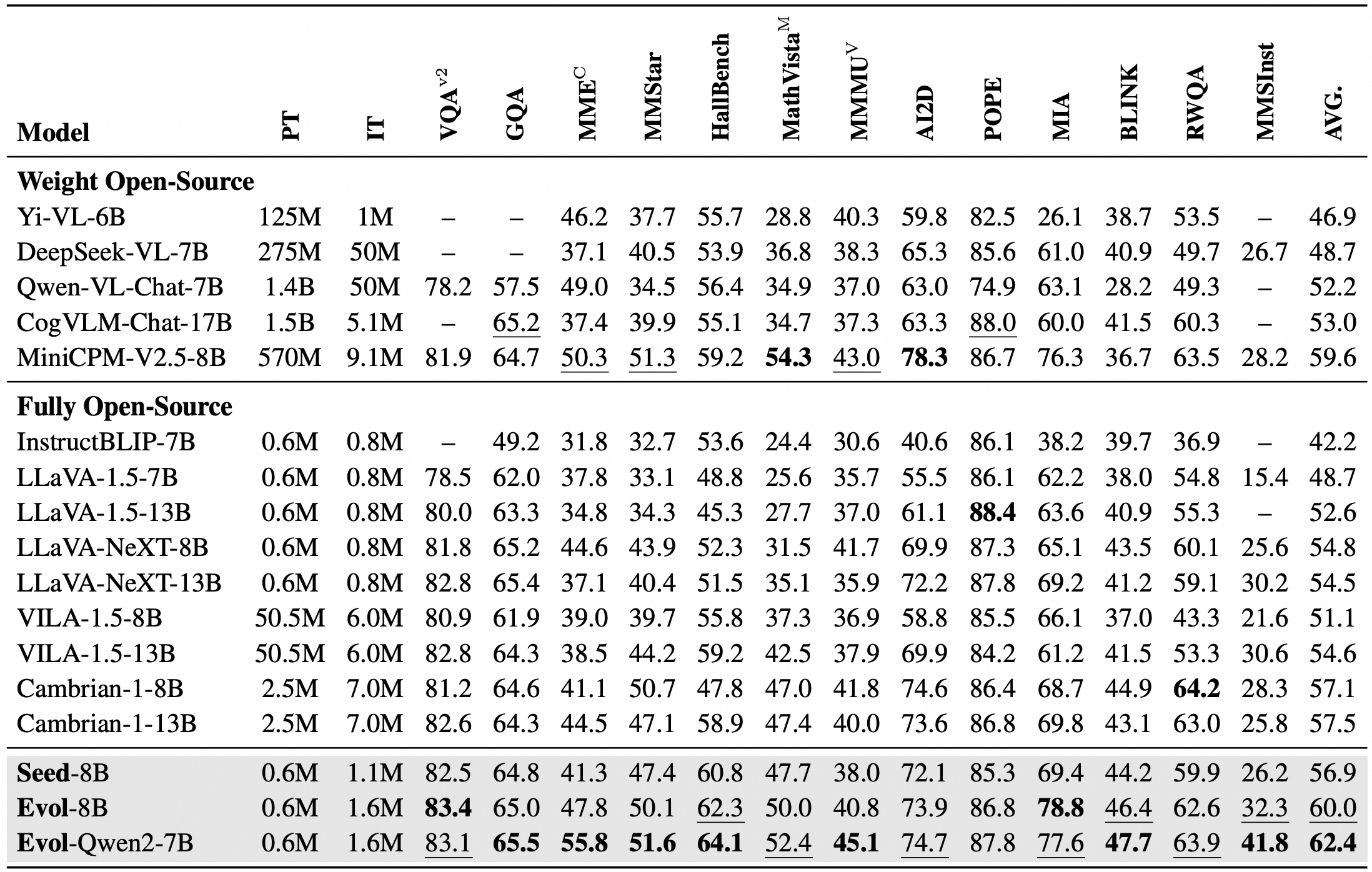
Comparison with state-of-the-art methods on 13 visual-language benchmarks : Our MMEvol consistently improve LLaVA-NeXT under a head-to-head comparison, using the same prompts and the same base LLM, showing the effectiveness of enhanced pretraining data quality. We mark the best performance bold and the second-best underlined.

Examples of image-text dialogue with our Evol-8B MLLM : Our model trained on evolved data exhibits strong visual reasoning, instruction following, and fine-grained perception capabilities. Additionally, it identifies nuances in meme content, validating the effectiveness and efficiency of MMEvol.
@article{run2024mmevol,
title={MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct},
author={Run Luo, Haonan Zhang, Longze Chen, Ting-En Lin, Xiong Liu, Yuchuan Wu, Min Yang, Minzheng Wang, Pengpeng Zeng, Lianli Gao, Heng Tao Shen, Yunshui Li, Xiaobo Xia, Fei Huang, Jingkuan Song, Yongbin Li},
journal={arXiv preprint arXiv:2409.05840},
year={2024}
}